KB000161
PRODUCT: K2.net 2003
LEGACY/ARCHIVED CONTENT
This article has been archived, and/or refers to legacy products, components or features. The content in this article is offered "as is" and will no longer be updated. Archived content is provided for reference purposes only. This content does not infer that the product, component or feature is supported, or that the product, component or feature will continue to function as described herein.
Improper design practices can limit the success of any solution. As such it is imperative to understand factors that should be factored into any K2.net development project in order to ensure proper system performance and scalability.
| Introduction Improper design practices can limit the success of any solution. It is imperative that the developer understands the various factors that affect a K2.net development project in order to ensure proper system performance and scalability.Contained in this article are some common issues that can significantly impact performance, scalability and manageability of K2.net solutions. Owing to the many variables that make up a production environment and as with most any discussions of this nature, there is no exact formula that can be applied to some of these issues. Every environment is unique with specifics environmental conditions e.g. expected volumes, user base, amount of data, hardware,etc. The intention is to highlight and discuss the various issues that may contribute to the performance, scalability and manageability so that they can be accommodated for during the design and development process. | |
| |
| Utilize different "Platforms" for the K2.net Worklist segregation | |||
| Whenever a client event creates a worklist item in K2.net a "platform" parameter must be passed in with the AddWorklistItem() method. This is done automatically within the code generated by K2.net Studio for a client event. By default, K2.net Studio uses the platform label of "ASP". When a client event is to be opened, such as by a user via the UI application, the K2ROM OpenWorklistItem() method is called with a serial number and the platform label. This concept is sometimes confusing. The default platform label "ASP" seems to imply that it must be related to ASP.net. In actuality, the platform field is simply a text value used simply to enable worklist filtering based upon types of worklist items. The default "ASP" platform does not need to be used; the developer can insert any appropriate text value. This is performed in the code that makes the AddWorklistItem call for the client event within K2.net Studio. Please keep in mind that the K2.net Workspace worklist and K2.net Task List SharePoint web part display only the default platform ("ASP") worklist items. Creating custom worklist platforms will result in worklist items not appearing in these two tools. In order to view these tasks, custom worklist retrieval functionality will need to be developed. | |||
|
There are many scenarios where this can be useful. Below are two examples: | |||
| 1) Segregate worklist items by technology | |||
| An organization has a specific client event that they would like to allow users to interact with via their desktop PC when they are in the office, or their mobile device when traveling. The default client event supports surfacing the event in multiple ways; by selecting the "Internet" and "Mobile" options. Once selected, the code can be generated and edited within K2.net Studio and the platform for the Mobile option can be changed to "MOBILE", while leaving the Internet option as "ASP". A custom worklist application is then created for mobile devices that return all worklist items assigned to this user on the "MOBILE" platform. When a user is in the office, and is interacting with the system via the K2.net Workspace Worklist on his/her PC, the users will see all the "ASP" platforms, which will open the regular ASP.NET form. When a user interacts with the system via a mobile device, he/she would open the custom mobile device worklist that displays only the mobile client events (as the custom worklist would search for the "MOBILE" platform tasks). That in turn would surface the client event appropriately formatted for the mobile device. | |||
| 2) Segregate worklist items by task | |||
| An organization creates a K2.net process that creates client events that need to be handled by actual people as well as client events that need to be operated in a batch like mode by some external application. The client events that will be worked by actual people could use the default "ASP" platform, while the client events destined for the batch process could be assigned a platform of "BATCH". The external batch application could then issue a K2ROM OpenWorklist call with the "BATCH" platform to retrieve all tasks that need to be operated on within the batch process. The benefits of this type of approach are realized as system volume grows. In a large volume environment worklist filtering becomes very important, as inefficient worklist generation can impact the overall user experience and system performance. The platform field is stored in the actual K2.net Worklist table, so it is a very quick and efficient way to filter, as no joins are required. | |||
| Externalize process data for efficient granular worklist filtering by business data | |||
| Generally, the K2ROM OpenWorklist method is utilized to implement custom worklist retrievals. However, in large volume systems where process data fields are desired to filter worklists, this can be inefficient. All process and activity data fields are stored in the K2.net database within a binary block of data, as opposed to being stored in their own dedicated columns or even name/value column pairs as done in K2Log. When an OpenWorklist method is called with a WorklistCritera object (the WorklistCriteria facilitates filtering and sorting by process and activity data), K2.net first retrieves all worklist items for this user and platform, then opens each worklist item individually to recover the data fields from the binary block of data to make the filtering and/or sorting decisions. On large worklists this can be a resource intensive process. For large volume scenarios where process/activity data fields need to be utilized to filter or sort a worklist, it is recommended that the specific data fields required in the search be stored in a database table external to K2.net, in addition to the native K2.net data field storage. The external table should contain a field for the K2.net "Process Instance ID" if querying process datafields or a "Process Instance ID" and an "Event Instance ID" if tracking activity level data. A query can then be constructed that joins the external table data with the internal K2.net _Worklist table, or more appropriately a read- only view on the _Worklist table (see below for a sample view). Please note the read-only view of the worklist table is the recommended interface to querying the K2.net Worklist. This query should then become the basis for the custom worklist application, ensuring that the fields necessary to process a worklist item in an application (generally the platform, serial number and URL for the event which is stored in the "Data" field), are accessible. To maintain this data in the external table(s), a server event(s) can be incorporated into the K2.net process that saves out the appropriate business data (via .NET assembly, web service, ADO.NET.). Having the K2.net process manage the saving of the data ensures that it is reflected in the external data source within the scope of this process execution; removing the need to develop some sort of external data synchronization process between the K2.net and external databases. Please note, that the process and activity datafields are stored as name-value pairs within the K2Log database. It may be tempting to leverage this data by joining to the read-only worklist view on the K2.net Worklist table, to avoid having to externalize the process data to a different data source. This should be avoided. By default the K2Log is populated via a set of low priority threads that operate asynchronously from the main K2.net runtime execution. Thus it cannot be guaranteed that the data will be there when needed. | |||
| Sample View | |||
| When needing to query the Worklist table directly from the K2.net database, it is recommended that a read-only, non-locking view be created and used. An example is provided below: | |||
|
CREATE VIEW [_ReadOnlyWorkList] AS
| |||
| This view can then be joined in to other tables (internal and external to the K2.net database) to generate an appropriate worklist. | |||
| Use server events before multi-destination user client events wisely | |||
| It is important to note, that this section is in no way meant to discourage the use of server events before a client event. It is mentioned to draw attention to how it can be used inefficiently. Whenever an activity instance is created, K2.net creates each event contained within the activity (in a top down order, as displayed in K2.net Studio) until it hits either an asynchronous server event or a client event. Once it hits one of these types of events it stops after the event is planned and awaits to be notified that an action has been taken. For an activity with multiple destinations, this process is repeated for each destination user (as each destination user gets his/her own copy of the activity, including all the events). It should be noted that there is a resource cost (CPU processing, memory usage, database processing and storage) with each event instance. Below is an example of an inefficient use and how it was corrected: In one K2.net process design review it was noticed that there were a number of activities whose first event was a server event that set some process data fields by reading some values from an external database. The next event in the activity was a client event. Many of these activities had twenty destination users. This meant that the server event that set the process data field was being executed twenty different times for each activity instance, when it only needed to execute once. From a data integrity point of view, it was not noticed because each event instance overwrote the same process data field twenty different times with the same values from the database. However, this was very inefficient when factoring the resource cost (as mentioned previously) of a single event instance. To put this in perspective with regards to scalability, each server activity was firing for all twenty destination users for this specific activity multiplied by potentially thousands, or tens-of-thousands, of times that activity may be hit within a day in a high volume environment. One solution to this scenario was to redesign the K2.net process such that the server event that was being called to set the process data fields was moved to a new activity that was fired immediately before the original activity containing the client event. This insured that the server event only fired once in the new activity, while not affecting the client event in the original activity. Another solution is to use the preceding rule of the actual activity. The preceding rule runs when the activity is attempted to be started. It is not affected by the number of destinations, as the destination rule executes after the preceding rule has completed successfully. Code can be placed in the activity and saved to a library. This sometimes works better if there is a need to execute the code on every activity and having a separate activity before every client event. | |||
| Never call K2ROM to operate on the current process instance from an event within the current process | |||
| The K2ROM should never be utilized within a server event to operate upon the current process instance. This includes directly accessing the K2ROM or accessing a business object/external assembly that contains the K2ROM. Attempting to use the K2ROM to operate on the current process instance from within the execution of the current process instance can result in inconsistent behavior and/or crashing of the K2.net Server service. This because is the K2.net server locks the processes that is currently executing and cannot connect back to itself with the external K2ROM as described. However, there are situations where this sort of functionality is required. For instance there may be a process level escalation that has a server event waiting to be completed. The only way to do this is by using the K2ROM to finish the event. In this case, the solution is to create a very simple K2.net workflow with one activity. The K2.net process should contain some datafields to be used by K2ROM (Serial Number, Server etc) and use the K2ROM here to connect to a workflow process and finish the event. Call this sub process from the main process where you need to use the K2ROM in the process and this will work as it connects to the sub process releasing the lock on the main process allowing the sub process to use the K2ROM to connect back. | |||
| Data on Demand | |||
| "Data on Demand" is a feature which minimizes the load placed on server resources when a large volume of data from the K2.net database is requested by the K2.net server and worklist. By default, when a process instance is loaded by the K2.net server all the data fields are loaded, regardless of whether they are needed at that time or not. This creates a resource drain as not all the data fields are required at the same time to perform a step within the process. However, since all the data has been loaded, the system must manage the data contained within memory even though only a small portion of the data may be affected at that time. If the "Data on Demand" feature is not enabled or if an older version of K2.net 2003 is used, all the data is transferred to the K2.net Server. It is then transferred again to the IIS server where the K2.net 2003 Workspace is hosted. The amount of data in memory can be problematic especially when filtering and/or sorting. Additionally the bandwidth limitations between the K2.net server and the SQL server can be the become an issue when handling large volumes of data. To make use of the "Data on Demand" feature, it must be enabled on a field-by-field basis from within K2.net Studio. When "Data on Demand" is active, only the fields required at that time will be returned by the server when the request for data is sent through to the server. In other words, the data must be "demanded" as an explicit call for it to be loaded into server memory and passed to the client application. To illustrate: To clarify this, when a process which has data fields with "Data on Demand" enabled, is loaded into memory, these data fields are not loaded with it, but rather only "pointers" to the data are created. Once the data is requested, the server will make a call to the K2.net database and return the data. This feature then economizes bandwidth usage in that only the data required is requested and loaded by the client application into local system memory, rather than loading unnecessary data from the server, to the client application. For more detailed information on "Data on Demand" within K2.net, please refer to KB000102 - K2.net 2003 - Data on Demand explained | |||
| Exception handling | |||
| While Exception handling is not necessarily an issue directly impacting scalability, proper exception handling can play an important role in administering a high volume system. It is imperative to understand how K2.net natively handles exceptions. K2.net will "bubble" the error up from the level it occurred in to the closest Exception Handler available. K2.net attempts to have exceptions handled in the following locations (and in this order): | |||
| |||
| Code level exceptions are handled via standard .NET Try-Catch blocks within the .NET code. The Event, Activity and Process level exception handlers are K2.net code blocks that can deal with any exceptions that occur within their respect scopes. So if an exception occurs within an event level code, K2.net will attempt to have it handled by a Try-Catch within the code. If there is no such Try-Catch block, it will be bubbled up to the Event level exception handling code block. If there is no such handler, then it will be bubbled up to the Activity level exception hander. If no such handler exists, it then bubbles up to the Process level exception code block. If there is no such handler then the K2.net server will trap the error and log it to the K2.net database. The process instance will then enter an error state. The actual error is viewable, and potentially repairable, via the K2.net Service Manager. | |||
| By default, the Event, Activity and Process exception blocks within a K2.net process are empty. The developer must explicitly enter in the function declaration, context reference and actual code handling. Below is an example of a Process/Activity exception handling code block that sends an email notification to someone: | |||
| [C#]
public void Main(ExceptionContext K2)
| |||
| [VB.NET]
public void Main(ExceptionContext K2)
| |||
| Please note that if the exception is handled via a Try-Catch block within the code, the following will occur: | |||
| |||
| There may be times where you need to do both; handle the error locally and have the process enter an error state. For these instances, you will want to handle the exception locally in the Try-Catch block, then throw a new exception so that it bubbles up through the proper K2.net channels. If you handle the exception in the Exception code block of Events, Activities or Processes: | |||
| |||
| Another suggestion would be to write .NET code within the K2.net Process level exception code block that logs the error to the Windows Event Log on the K2.net Server. This permits Event Log monitoring tools, like Microsoft Operations Manager (aka "MOM"), to detect the error and issue notifications just like any other monitored application within the organization. There is no stated Best Practice for exception handling as this varies widely by customer standard and business requirements. For example, some K2.net customers have a standard logging component that is embedded in all .NET applications. In this case they will need to incorporate it into the appropriate location in the K2.net exception handling code blocks. Other projects dictate that certain error conditions should not stop the process, which also needs to be handled accordingly. The best thing any K2.net developer can do is understand how K2.net exception handling works and then make a decision that aligns with the needs of the business process and corporate standards. | |||
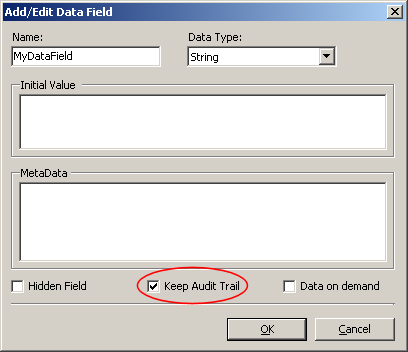
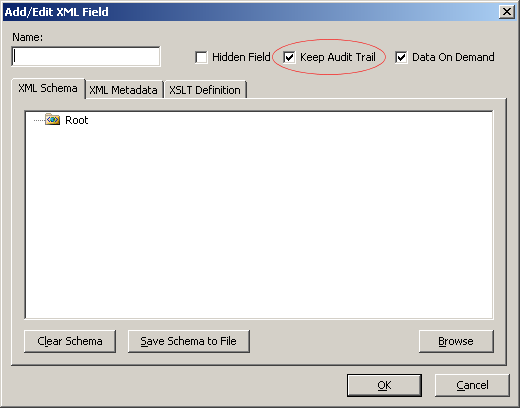
| Keep Audit Trail | |||
| The "Keep Audit Trail" option enables you to keep track of the changes made during the execution of the workflow process. This option is selected by default when a data field is created. Audit Trail adds overhead to the database size and growth over time, because each time a data field that has this option set is changed a copy of the before and after data along with additional metadata is stored in the K2Log database. For this reason this option should be used with care when large data fields and XML Fields are involved. | |||
|
| |||
|
| |||
| Impact of storing large objects in the K2.net process data | |||
| Since K2.net is not designed as a document storage system, it is not recommended to store large objects (e.g. complete documents, large binary objects) in process data, due to the impact of such objects on the K2.net database's growth over time. It is recommended to store these objects in a system specifically designed for storing such information (for example, a document repository such as SharePoint), and storing a reference to the document in K2.net process data. If it is absolutely necessary to store such large objects in process data, it is recommended to disable the audit trail on these fields and, once the document or object is no longer required, to remove the value from the data field and set the value to empty. | |||
| Impact of activity data fields | |||
| When defining activity-level data fields or XML fields, it is important to bear in mind that each destination user for the activity will receive its own copy of the activity-level fields when the activity is created. In other words, if an activity contains 10 data fields and the destination rule for the activity is a group with 100 users, each of the 100 destinations will get a copy of each of the 10 data fields. The impact on database growth is obvious, especially if audit trails are also enabled on these activity level data fields. It is recommended to only define activity-level data fields when it is required to capture the individual destination users' input, for example, when it is necessary to evaluate all the destination users' input. A rule of thumb is to use activity data fields only when more than one slot exists for the activity's destination rule. | |||
| Number of process data fields | |||
| The number of data fields defined for a process also plays a very important role in K2.net 2003 performance and database size. When the number of data fields gets too high it should be considered to include all fields in an XML document rather than having all created as process data. Below are some important information in regards to process data field types and the impact it has on the K2Log database (The K2.net Transaction database is not taken into account as it grows and shrinks automatically over time as processes are started and completed):
| |||
| Referenced assemblies | |||
| When assemblies are referenced from the file system (as opposed to the GAC) in a K2.net Project, the assemblies are serialized and exported to the K2.net databases along with the process definition. If versioning is not a consideration on these referenced assemblies it should be considered to copy the assemblies to the /bin folder on the K2.net server. (Default location: "C:\Program Files\K2.net 2003\bin") The K2.net Server will first look for the assemblies in this folder. If they are not found the assemblies will be loaded from the database and deserialized. A slight performance advantage can be gained if the assemblies already exist in the /bin folder since the K2.net Server does not have to create the assemblies at runtime. The order of locations the K2.net Server searches for referenced assemblies is as follows: | |||
| |||
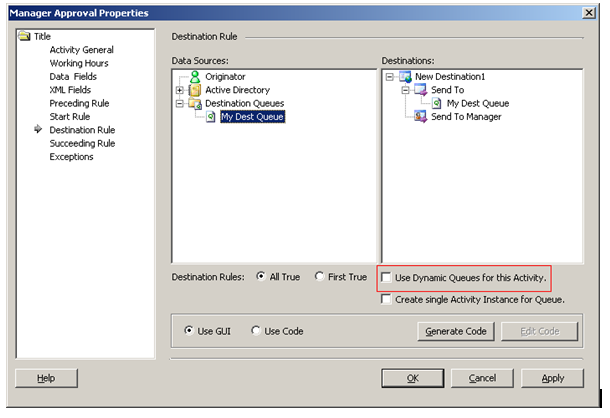
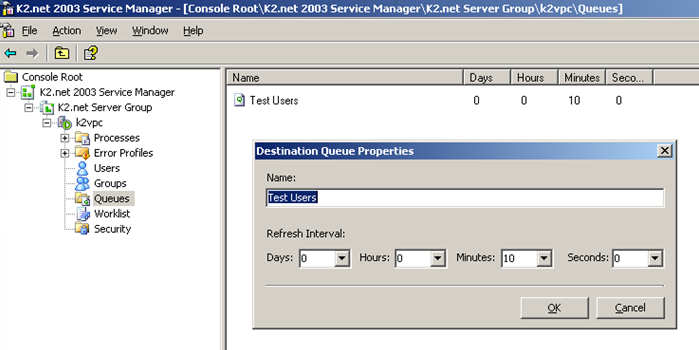
| Destination Queues | |||
| When Active Directory (AD) Groups are used as destination for activities, it is recommended to make use of destination queues. This will allow K2.net to 'keep up' with changes to the group membership that may be made in AD. Depending on the business' requirements, it may be necessary to enable 'Dynamic Destination Queues' on the activity where the destination queue is used (see screen shot below). This option will manage task items assigned to the group dynamically. For example, if a task is assigned to a group of users and a user leaves the group, K2.net will remove the task from that user's worklist when the group membership is refreshed. (Note that this will only happen if that user has not yet opened the task.) Similarly, if a new user joins the group, the task will be added to the new user's worklist should it's status be 'available'. | |||
|
| |||
| The refresh interval for groups depends largely on how often the group membership is expected to change. The default refresh interval is 10 minutes, but this may be excessive when a group's membership only changes once a month. In this case, a refresh interval of once a day will be sufficient. Also, when many queues are in use, it is recommended to spread the refresh interval over time. This prevents K2.net from refreshing all queues at exactly the same time which can lead to performance issues when those queues are needed for running process instances. A method of achieving this is to set the queue refresh interval for the different queues to different prime numbers. Destination Queue refresh intervals are set within K2.net Service Manager. | |||
|
| |||
| Number of destination users | |||
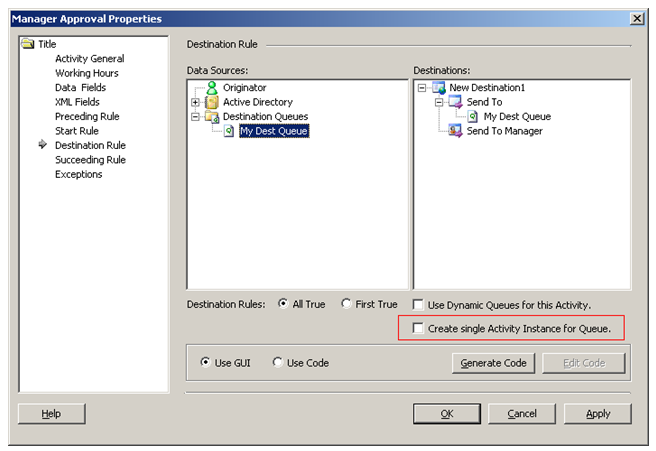
| A high number of destination users for activities with client events can cause severe performance issues on the K2.net Server. This comes into play when a large number of users access the Worklist simultaneously (or calls from the K2ROM API to user worklists) and a high volume of data has to be returned to the K2.net Server from the database. In conjunction with the "Data on Demand" it can be alleviated. Another consideration is the amount of activity level data in these situations. For example, a process has an activity that is contains a client event and 25 destination users, but only one slot. This activity also has a large activity XML field. Every day 100 instances of this activity are started. This means that there are 2500 copies of the XML data field created each day (200 activity instances X 25 destination users / instance). With the arrival of K2.net 2003 Service Pack 3 (SP3), there is now an alternative way to handle this. SP3 introduced the option to create a single activity instance for an activity when a Destination Queue is used as the activity destination. The new feature creates a single Activity Instance for the Destination Queue. K2.net Server will create only one activity instance which is visible to all users within the Destination Queue. When one of the users opens the item it will no longer be visible in the other user's tasks lists but will have been assigned to the user who opened it. The implications however are that only one slot is available. The advantage is that only one activity instance is created in the database significantly reducing database overhead as well. To enable this feature, select the appropriate check box within activity's Properties window: | |||
|
| |||
| Code Modules Code modules usually contain functionality shared between processes in the same project. A code module is similar to a class in a Visual Studio project – the code module must be instantiated in the calling code and the relevant methods called.
It is recommended to use code modules when:
Below is an example of how to implement code module within K2.net: | |||
| [C#]
'Code that is stored in the Code Module:
| |||
| [VB.NET]
'Code that is stored in the Code Module:
| |||
| Configuration settings In general K2.net development configuration settings are typically stored in .config files or in string table entries. It is not recommended to store such settings in plain text or other XML files, since the XML document object or text file object is resource-heavy and may affect performance on a busy K2.net Server. If a configuration file approach is preferred, a file named K2Server.exe.config must be created to be able to use the System.Configuration.ConfigurationSettings.AppSettings namespace. This file must exist in the same directory as the K2Server.exe program (this is located in the /bin folder on the K2.net Server install directory, by default <drive:>\program files\K2.net 2003\bin) | |||
| Configuration File | |||
| This configuration file should have the following structure: | |||
| [K2Server.exe.config] <?xml version="1.0" encoding="utf-8" ?> [C#]
String MyKeySetting = System.Configuration.ConfigurationSettings.AppSettings.Get("MyKey"); [VB.NET]
Dim MyKeySetting as String = System.Configuration.ConfigurationSettings.AppSettings.Get("MyKey")
| |||
| Note that string table entries are strings so one cannot directly store a collection of values in a string table entry, unless the values are separated by a unique character such as "|" and the code that reads the string table entry splits the string value into a collection. The recommendation is to store values that may change constantly in a string table entry. Values that will remain constant may be stored in a configuration file or in string table entries. Complex value structures will have to be stored in a configuration file unless the string value can be manipulated to rebuild the complex structure. A security consideration is that the configuration file is a normal text file stored on the file system. If this configuration file contains sensitive information (e.g. usernames and passwords for connecting to data stores), this file must be well protected with limited read rights. The K2.net Service account will need read rights on this file. | |||