K2.net® 2003 Scalability, Clustering and Sizing
KB000103
PRODUCTSEE ALSO KB000123: Basic Guide to enabling a K2.net 2003 Implementation to use Kerberos Authentication
TAGSThis document is intended to provide an overview of what type of clustering K2.net® 2003 supports. At this point in time K2.net® 2003 with Service Pack 2 (SP2) is the latest version and is not cluster aware, it will however; fully support Network Load Balancing (NLB). There is one type of clustering which K2.net supports: NLB (Network Load Balancing)
| ||
Introduction | |
This Knowledge Base Article provides an overview of the types of clustering K2.net® 2003 supports. Currently K2.net 2003 is not cluster aware, it will however; fully support Network Load Balancing (NLB). | |
The following types are of clustering are supported: | |
| |
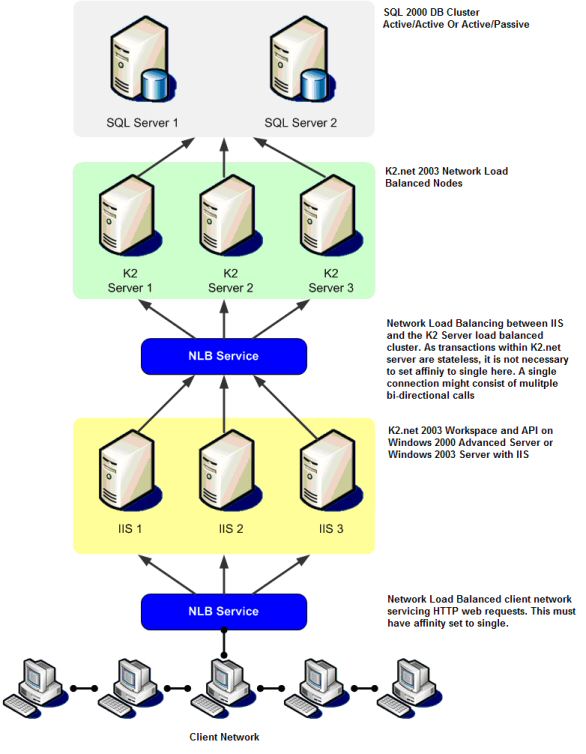
| The above mentioned clustering options both have their inherent advantages and disadvantages, extending to deployment complexity and implementation cost. For the purpose of a standard NLB installation, K2.net 2003 Server, Workspace and the IIS (Internet Information Service) would usually share a server with a fully clustered version of SQL Server 2000 operating on the backend (often on a SAN). With other installations, the K2.net 2003 server has a dedicated server separate from the IIS and Workspace implementation as shown in Figure 1: K2.net 2003 NLB deployment scenario. | |
| What is NLB? | |
| Network Load Balancing can be implemented in 2 ways namely: hardware - or as software. The pros of hardware are obvious, complete abstraction, no impact on the actual server running as part of the NLB - it remains blissfully unaware, and very often hardware solutions include extras like compression. The con with this is the cost. | |
| The software version also has a couple of important pros too, like: it comes as part of the installation for Windows 2003 and Windows 2000 Advanced Server. It requires zero additional expenditure for some very good benefits. The only real con with software NLB is that a certain amount of CPU time is consumed by heartbeat monitoring and filtering for each node in the cluster. The actual figures seem pretty irrelevant when all is taken into consideration, but as a rule of thumb, budget about 1.5% of CPU time per NLB node. (There are a few dependencies on this, but for a general idea this is fine - also, the NLB cluster will currently support up to a maximum of 32 nodes.) | |
| There are certain things to note when contemplating NLB installations. For K2.net Workspace as with many ASPX applications, session state is absolutely required. This means that the affinity within the NLB must be set to single. There are 3 types of affinity supported by NLB: | |
| |
| If all the clients at a specific installation are running through the same client-side proxy then all clients will appear to have the same IP address. Due to the configuration of the algorithm, all of these calls will be serviced by the same server - hence NLB will not work. A very important consideration here is NATting (Network Address Translation). If client calls go to a router that is NATting these unique client IPs to a specific IP address then as single affinity is selected in this case the NLB algorithm will send all the traffic to a single server node within the NLB. Remember, NLB determines mapping via the incoming IP address. | |
| The NLB algorithm does not take into account server load at run time. This means that calls are routed according to the incoming range of IP addresses. It also means that for a narrow IP address range, a single server in the NLB may field all incoming requests. The following rule of thumb should help determine whether even distribution can be attained: 1 server for every 5 clients. So, if you have a 2 node NLB you should be getting in at least 10 client calls to see evenly distributed load. | |
| All nodes in the NLB will receive all packets, regardless of which host the packet is intended for, the NLB algorithm is essentially a filtering algorithm, the net effect being that the host for which the packets are intended fields the request, and the others simply discard the packets. | |
| The recommended setup of the NLB nodes is two NIC's (Network Interface Cards) per node. One NIC will be load balanced, the other one will handle inter server communication and can be setup using metrics to cater for all outbound traffic, freeing the NLB NIC for incoming traffic. | |
| The chief goal of NLB is for high performance. | |
| System Architecture | |
| Here is a typical system architecture diagram that illustrates the best practice implementation of K2.net 2003 for an organization with a large number of concurrent workflow users. | |
| | |
| Explaining the Diagram | |
| With reference to Figure 1: K2.net 2003 NLB deployment scenario, what is shown is the best practice for performance in a NLB and clustering deployment scenario. From the top down, we have a SQL Server 2000 cluster. Whether the actual configuration is active/active or active/passive is irrelevant. K2.net only needs to be able to communicate with the databases; the actual implementation of the database cluster will make no difference to K2.net as long as it is accessible. | |
| Directly under the SQL Servers is an NLB implementation of K2.net Server. The NLB service shown is just that, there are only 3 boxes in this NLB configuration, the NLB runs as a service at the network level on all of the servers; hence there is no fourth box managing the NLB. If a node were to fail at this point, the other two would split the work across them and carry the load (subject to the NLB algorithm). It is important to note that a failure in this sense means a server failure, not the failure of an individual service on the server. Things that usually cause a server failure are: | |
| |
| Under these circumstances NLB will support a type of failover see: "What Constitutes a Failure in NLB?" for more information. What happens now is that by default the other servers try for 5 seconds to contact the failed server; if they fail for 5 seconds (this is configurable in the registry on all machines to be in the range of 1000 to 10000 milliseconds) they move into a system state called convergence called convergence. Convergence occurs when the remaining server nodes in a NLB split the missing server's load to continue handling the incoming requests. Convergence will also occur when the failed server comes back on line - convergence can take between 2.5 and 3 seconds. A specific affinity setting is not required here as the K2.net server does not maintain any status information. The Workspace in this instance must be explicitly stated in its web.config file to point to the virtual NLB name or virtual IP address. | |
| The following section (in yellow) is the IIS with K2.net 2003 Workspace implementation of NLB. Again, the 3 machines are all part of the NLB. The difference with this NLB and the previously mentioned one is the affinity setting. For incoming client requests in a web based environment where session state is maintained, the affinity setting must be set to single. The only time state information would be lost in a case like this is due to node failure causing convergence. The clients will connect to the virtual NLB name or virtual IP address and not directly to a named server or real IP address. | |
| For this implementation to function correctly, Kerberos authentication must be deployed. For the standard type of NLB implementation, NTLM authentication will suffice, as K2.net Server and IIS reside on the same box and the SQL server is only a single hop away. | |
| What Constitutes a Failure in NLB? | |
| One of the largely confusing terms of clustered environments is that of high availability. What does high availability mean? It means continuous operation of a system in the event of downtime. High availability is the quest for 100% server uptime (from the client's perspective). Downtime of a server can be for an entire range of differing calamities but usually deals with some sort of hardware or network failure. In an NLB environment, the K2.net 2003 Servers communicate with each other via a type of heartbeat.
| |
| Assume that there are two K2.net 2003 Servers running in a NLB environment. If server number 1 and server number 2 are both up and running, then both of the servers are sending each other small heartbeat messages via the network to check that they are receiving communication from each other. If server number 1 were to fail (the failure in this case being actual server failure, or K2.net 2003 Server failure) then server number 2 would log errors in its k2error.txt file stating that it could not contact the other NLB K2.net 2003 Server. This means that server number 2 is aware of server (or the service) in server number 1 having failed, but it does not take specific action around this. For the K2.net 2003 Server to take specific action around this it would need to be running as a cluster aware service in a clustered environment (which K2.net 2003 currently does not support). Take note that NLB does not take into account even CPU usage and memory usage when routing clients. It runs at the network level and is as such not specifically aware about the state of the host server's health at any point in time. If a single service has terminated on the box, even if the user manually shut it down, NLB will continue to assume that the service is active and route traffic to it based on client IP address. | |
| Now, take the above example and extend the failure from the K2.net 2003 service to the actual server. Assume the actual server lost all power due to a power supply failure. The NLB service detects that a node has disappeared; it tries by default for 5 seconds to contact this failed node. Failing that it proceeds to the convergence state and once converged it will re-route any traffic being fielded by that server to the remaining server node in the NLB. This entire process can take up to 8 seconds, but it is now an example of high availability of sorts and it is implementing a type of failover. This failover only works for the situation where the actual network load balance service fails to communicate with the hosts via its heartbeat. | |
| Hardware Planning for K2.net 2003 | |
| This section outlines the recommended hardware specifications of the machine(s) to host the various components of K2.net 2003. | |
| With reference to the diagram above, there are essentially three tiers that must be considered when planning or scaling a K2.net 2003 implementation. | |
| SQL Database Tier | |
| On the SQL Database tier (light blue), it is highly recommended that the SQL Database tier be put on physically separate machines from the K2.net Server tier and IIS Web Server tier. In this tier, the focus falls on both machine memory and CPU power, or the number of CPU's. As K2.net workflow execution involves significant database activity, it is essential that the database server's hardware meets or exceeds the machine hardware specifications recommended for machines in the K2.net Server tier. | |
| The SQL Database storage sizing depends on the number of workflows, complexity level of each workflow, the expected number of instances, the number of data fields defined in each process instance, etc. Please use the Data Size Estimator Excel worksheet to get an estimation of your database needs. | |
| K2.net Server Tier | |
| The processing power need of the K2.net Server tier (green) relates directly to the volume of concurrent processes and worklist calls which workflow users initiate. | |
| In other words, a single CPU may easily handle thousands of concurrent workflow users if they rarely generate processes or open worklist items. This, of course, is highly unlikely. It is therefore important to understand that the sizing of the K2.net Server tier depends on the volume of processes generated by the connected users and not necessarily the number of connected users. On K2.net Server tier, the focus is always on the number of CPUs and their combined processing power for rapid execution of workflow and work item requests. Generally, a single CPU will be able to support up to 250 concurrent workflow users. | |
| Generally, for a cluster or NLB, each individual machine's processing power should be strong enough to hold 100% load should one fail. To explain this, consider the K2.net Server example of 3 servers. If all of these servers run at 60% and a single server were to fail, half of the 60% load on the failed server would be transferred to the other 2 servers, which would now both need to run at 90% each until the failed server was brought back on line. Bear in mind that the more servers, the higher the tax on the CPU for the NLB algorithm so this is not an exact science. | |
| IIS Web Server Tier | |
| What one should not forget though is the IIS tier (Web Server). The IIS sizing depends on the number of users concurrently connected through one IIS node to a K2.net Server. On the IIS tier, focus falls more on both machine memory and CPU power, or the number of CPUs. The K2.net connection is created and maintained in memory on this tier, and all worklist items are cached and rendered through IIS to the web client. | |
| Remember that in IIS is it very important to find a balance between caching and serving new pages and the Workspace is dynamic and will generally change regularly. Also, by default IIS will not take more than half of the available RAM, this can be modified by editing the IIS metabase, but it is not recommended and does not form part of this document. | |